
Существует несколько способов реализации операции UPSERT в BigQuery. Об одном из таких способов я расскажу в этой статье.
Для начала давайте представим, что у нас есть таблица из двух полей id и name:
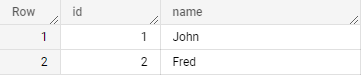
Мы хотим выполнить UPDATE записи по ключу id, а если значение с таким ключом не найдено, то выполнить INSERT.
Для этого я предлагаю воспользоваться оператор MERGE в сочетании с ключом id, по которому будет производиться сопоставление записей.
Пример запроса, который реализует операцию UPSERT, может выглядеть следующим образом:
MERGE `mydataset.mytable` t
USING (
SELECT 1 AS id, "John" AS name UNION ALL
SELECT 2 AS id, "Jane" AS name UNION ALL
SELECT 3 AS id, "Bob" AS name
) s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET name = s.name
WHEN NOT MATCHED THEN
INSERT (id, name) VALUES (s.id, s.name)
Этот запрос объединяет таблицу mydataset.mytable с временной таблицей s, содержащей новые записи для вставки или обновления.
Оператор MERGE сопоставляет записи по полю id, и если запись с таким id уже существует в таблице mydataset.mytable, то выполняется обновление ее поля name значениями из временной таблицы s. Если же запись с id отсутствует в таблице mydataset.mytable, то выполняется ее вставка вместе с соответствующими значениями полей id и name из временной таблицы s.
В результате выполнения запроса выше получаем:
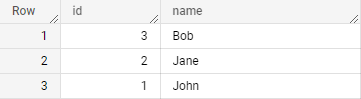
Таким образом, оператор MERGE позволяет эффективно реализовать операцию UPSERT в BigQuery. Однако, стоит помнить, что этот оператор может иметь высокую стоимость выполнения, особенно для больших таблиц, и необходимо проверять его работу на практике.

Оставить комментарий